Le machine learning : quand les ordinateurs prédisent l’avenir

Le machin what ?
Le machine learning, ou apprentissage automatique en français, est une branche de l’intelligence artificielle où « l’intelligence » est construite en se référant à des exemples. Le machine learning n’est pas nouveau (plusieurs décennies de recherches) mais le concept connaît un engouement ces dernières années qui n’est pas déconnecté de l’essor du Big Data. Mais commençons par le commencement. Arthur Samuel (un pionnier en matière d’intelligence artificielle) avait définit le machine learning comme « le domaine d’étude qui donne aux ordinateurs la capacité d’apprendre sans être explicitement programmé ». Cette définition, qui laisse un peu songeur, est quand même vague. Aujourd’hui, Tom Mitchell en donne une définition un peu plus moderne : « Un programme informatique se dit d’apprendre de l’expérience E par rapport à une catégorie de tâches T et mesure de la performance P, si sa performance à des tâches T, telle que mesurée par P, s’améliore avec l’expérience E. “
Ce qu’il faut retenir, c’est que le machine learning va créer de la valeur à partir de données.
Hello world !
Pour comprendre, le mieux est encore de prendre un exemple, et l’exemple de référence en machine learning, (son « hello world », pour les apprentis geek) c’est la classification des iris (on aurait préféré des chats, faute de quoi on se contentera de fleurs). Vous l’aurez compris, la première utilisation du machine learning va être la prédiction : on veut déterminer à quelle espèce un iris appartient. C’est assez simple car on peut catégoriser (le terme exact en machine learning est classification) un iris en fonction de 2 caractéristiques : la longueur et la largeur d’un pétale. Il nous faut tout d’abord un jeu de données d’iris avec ces 2 informations et l’espèce correspondante. Graphiquement, cela donne à peu près ça :
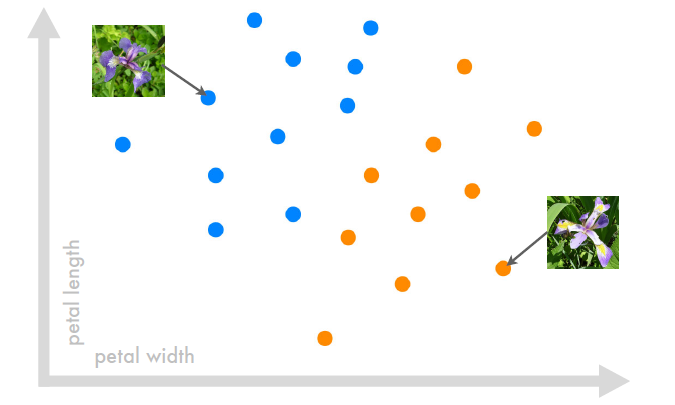
On voit aisément que l’on peut tracer une droite qui vient séparer les iris en 2 groupes distincts, l’espèce bleu et l’espèce orange. La droite va représenter l’algorithme de classification (ici simplifié à l’extrême) : C’est la phase d’apprentissage du modèle.
Si on a maintenant un nouvel iris sans connaître son espèce, on va pouvoir la prédire (ici, si il se trouve à gauche ou droite). En machine learning, on parle d’un nouveau « input » (la largeur et la longueur) pour lequel on va prédire « l’output » (l’espèce) le plus probable. C’est la phase de prédiction. Pour simplifier cela revient à identifier le nouvel iris parmi les espèces connues en fonction de la longueur et de la largeur de son pétale. On remarque qu’on aurait pu tracer d’autres lignes pour séparer nos 2 groupes, et donc changer certaines prédictions. Mais ça, c’est la science des algorithmes (choisir la meilleure ligne possible, donc le meilleur modèle).
Ce type d’exemple s’appelle de l’apprentissage supervisé : on a un jeu de données dont on sait à l’avance les outputs. On peut donc résoudre le problème de classification (les iris) mais également de régression (l’output est alors une valeur numérique, comme le prix d’une maison). Il existe cependant un autre aspect du machine learning qui est quant à lui un apprentissage non supervisé.
L’apprentissage non supervisé
Dans l’apprentissage non supervisé, on dispose uniquement de données brutes (sans output) et on va essayer de trouver une structure, c’est-à-dire, tenter de former des groupes (appelés clusters). En langage courant cela revient à prendre une grosse quantité de données, sans savoir ce qu’elle contient, à qui elle appartient ou quel est le type de ces données, et à l’aide d’un programme, d’en trouver une structure, de les regrouper en clusters non connus à l’avance. Pour reprendre l’exemple des iris, c’est comme si l’on tentait de regrouper les fleurs de largeur et de longueur de pétales similaires pour les considérer comme une espèce. C’est ainsi que Google news scanne tous les jours des centaines de milliers d’articles du web et les regroupe en reportages cohérents (allez sur news.google.fr, et cliquez sur « à la une »).
On note ainsi que l’apprentissage non supervisé est utilisé dans beaucoup de domaine, comme en marketing pour segmenter une clientèle où l’on obtiendra un résultat plus perspicace et valorisable en utilisant la totalité des données à disposition (et pas seulement l’âge ou la redondante « CSP»).
Vous avez saisi l’essentiel, regardons maintenant les applications
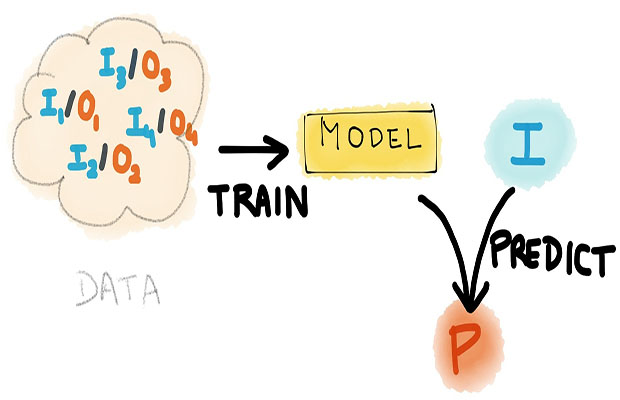
Les possibilités sont alors presque infinies. L’application qui fait beaucoup parler d’elle est la détection du churn. Le churn, c’est quand un de vos clients résilie son abonnement. Si on peut le prévoir, on peut engager des actions correctives (comme par exemple une offre promotionnelle personnalisée) et éviter ça. Cette anticipation peut se faire en analysant comment le service a été utilisé ces derniers temps (en fonction des caractéristiques du client et du contexte).
Un autre exemple qui parlera à tout le monde : les assistants virtuels, comme Siri. Le machine learning est ici une composante essentielle, que cela soit au niveau de la reconnaissance vocale (transformer le message audio en requête texte que le programme peut interpréter, car oui, à la base, un programme ne peut comprendre qu’une suite de 0 et de 1) mais aussi également pour reconnaître le type de requête qui peut être traitée et en extraire les paramètres (par exemple, si l’on veut enregistrer un rappel, extraire le nom de la tâche et l’heure – « rappelle moi d’aller chez le médecin à 14h, mardi»).
Une dernière application ? En médecine cette fois, pour le diagnostic en fonction des symptômes (coucou Dr. House). Au lieu de se baser uniquement sur leur propre expérience, les médecins (grâce à la puissance de calcul des ordinateurs) vont pouvoir considérer bien plus de cas d’ancien patients avec aussi beaucoup plus d’informations sur eux. Ainsi, grâce à la masse de données collectées, l’exactitude des diagnostics est grandement améliorée, et on peut engager des traitements préventifs.
On notera aussi la présence du machine learning dans la détection des spams (Gmail Priority Inbox), la reconnaissance faciale (autosuggestion quand vous sélectionner une photo sur Facebook) ou encore dans l’analyse de sentiment d’un tweet (fr.mention.com), la détection des fraudes, les opportunités de cross et up selling, ect… Bref vous l’aurez compris, le machine learning est omniprésent !
Mais le meilleur reste à venir ! Car si pendant longtemps, les techniques de machine learning nécessitaient des investissements coûteux et des connaissances précises, aujourd’hui tout est rendu très simple et accessible à tous, sans connaissances techniques poussées, grâce aux API prédictives.
Les API prédictives : des opportunités business extraordinaires

Les API prédictives sont des sites et applications qui vont vous permettre de réaliser vos travaux de machine learning facilement, grâce à la puissance de calcul du cloud (on parle alors de machine learning as a service – MLaaS). De nombreuses entreprises (Amazon, Microsoft…) ont également lancé leur service de machine learning.
A l’image des assistants de création de site web comme wix ou wordpress, des sites comme bigml.com vont simplifier l’ensemble du processus. Vous n’aurez plus à vous soucier des questions techniques (algorithmes, code, ect…), en revanche, il faudra vous poser les bonnes questions d’ordre “business”.
Pour ceux qui serait intéressé, voici le framework de référence pour structurer son application
- Who: Qui va utiliser l’application/où?
- Description: Quel est le contexte et qu’essaye-t-on de faire?
- Question asked: Comment écrieriez-vous, en français, la question à laquelle le modèle prédictif doit répondre ?
- Input: Sur quoi ce base-t-on pour faire la prédiction?
- Features: Quel aspect de l’input considère-t-on?
- Output: Qu’est que le modèle nous donne en retour?
- Data collection: Comment obtient-on les exemples input-output pour entraîner le modèle?
- Predictions: Quand est-ce que sont fait les prédictions et que fait-on une fois qu’on les a?
- Value: Comment la valeur est créée pour l’utilisateur final?
Pour conclure
Le machine learning apparaît donc comme un bon prédicateur grâce à l’analyse poussé des données du Big Data. Un dernier mot cependant, car le machine learning n’est pas parfait. Pour fonctionner correctement, le jeu de données de base (les exemples) sur lequel le modèle va être construit doit être fiable (ce qui est très dur à obtenir en réalité). De plus, celui ci n’est pas prêt de détrôner Nostradamus : et oui, comment prévoir des situations inédites dont on ne connait pas les ressorts a priori et qui sont donc, par définition, imprévisibles.



{kind=link}
Retrolien : Notre récapitulatif et analyse de l’E3 2017 – Victor Droin Blog Personnel
Retrolien : Revue de presse du monde digital (du 15 au 20 Février 2016) - Toile de Fond
Retrolien : Revue de presse du monde digital (du 15 au 20 Février 2016) - Toile de Fond
Retrolien : Revue de presse du monde digital (du 08 au 13 février) - Toile de Fond