Qu’est-ce que l’analyse de données sémantiques ?

Les récents événements survenus à l’encontre de Facebook, du fait de l’exploitation controversée de données par Cambridge Analytica, ont à nouveau ouvert les yeux du grand public sur la potentialité des données que nous partageons quotidiennement sur Internet.
En effet, chaque commentaire sur Facebook, chaque tweet, chaque article de blog, chaque post sur un forum ou encore chaque avis déposé sur TripAdvisor est une source d’information précieuse. Au travers de ces prises de paroles écrites (ou verbatims) résident le comportement des consommateurs, leurs envies, leurs attentes et leurs suggestions. De nombreuses entreprises cherchent à se rapprocher de leurs clients. À l’heure du marketing « one to one » les données sémantiques représentent l’opportunité de s’adapter aux propos des internautes. Analyser ces données peut permettre de mieux comprendre leurs attentes, développer un référencement en adéquation avec leurs requêtes, rendre plus intelligents des assistants virtuels.
La question est donc de savoir comment traiter et analyser cette donnée afin de l’exploiter et d’en tirer de puissants insights. C’est ici qu’intervient l’analyse sémantique (qui s’intéresse au sens des mots). En s’attachant dans un premier temps à analyser la structure d’un énoncé, elle permet par la suite de comprendre le sens, les thématiques abordées voire les sentiments contenus dans un verbatim. Nous présenterons dans cet article quelques grandes lignes et grands concepts de l’analyse de données sémantiques.
Un élément central : le traitement automatique du langage
Afin d’analyser une grande quantité de données il est coutume d’utiliser des algorithmes (oui, le Big data pointe son nez). Pour étudier vos millions de posts récoltés (dans une langue uniformisée de préférence), il convient de passer par un élément primordial, le Traitement Automatique du Langage Naturel (TALN ou Naturel Language Processing, NLP). L’analyse de verbatims repose sur une première étape mélangeant informatique et linguistique. Plusieurs méthodes, procédés et processus existent et nous n’entrerons dans les arcanes de ces derniers, l’objectif visé étant la vulgarisation du principe. Il est possible de distinguer 5 grandes étapes inter-communicantes :
- La segmentation du texte en mot ou unité lexicale, souvent délimité par la ponctuation
- L’identification des propriétés de ces mots (verbe, adjectif, nom, adverbe, pronom, etc…)
- L’identification des groupes auxquels ils appartiennent (syntagme nominal, syntagme verbal etc..)
- La compréhension du sens de la phrase ou énoncé analysé
- La compréhension de cet énoncé dans un contexte global
Ces 5 étapes ne sont pas à concevoir comme un enchaînement chronologique mais comme des étapes qui interagissent entre elles. Une métaphore intéressante afin de vulgariser l’analyse de données sémantiques est de comparer le fonctionnement de l’algorithme au raisonnement utilisé en grammaire en école élémentaire. À la manière d’un élève, l’algorithme va décomposer une phrase et comprendre le sens des mots en fonction des relations qu’ils ont entre eux. S’il détecte un verbe, il y a forcément un sujet qui a de fortes chances d’être un nom ou un pronom. Ainsi, c’est notamment grâce aux relations que les mots ont entre eux que les algorithmes sont capables de segmenter et identifier un énoncé. Il existe aussi d’autres procédés d’analyse, tels que la morphologie, que nous vous invitons à découvrir si le sujet vous intéresse.
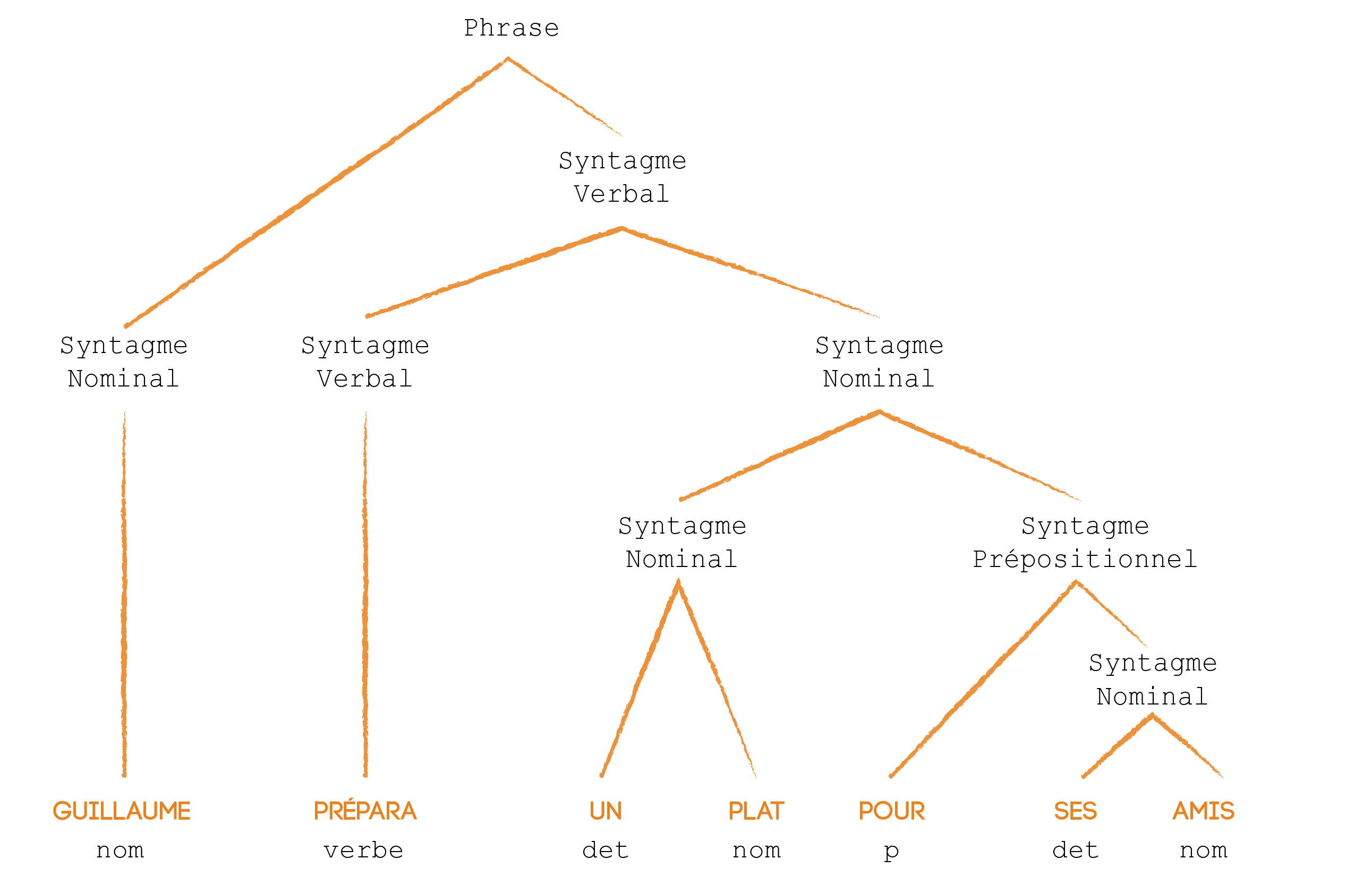
Illustration d’un arbre syntaxique avec l’énoncé : « Guillaume prépara un plat pour ses amis »
Des limites ?
Cependant il existe certaines limites à ces algorithmes. L’interprétation et la qualification des émotions restent un obstacle parfois complexe à franchir. Des lexiques de subjectivité/émotion et techniques de classement peuvent permettre de qualifier le sentiment d’un verbatim. Ainsi il est possible de savoir que l’énoncé « La pomme que je viens de manger est excellente » a une connotation positive. La présence de l’adjectif « excellent », faisant partie d’un éventuel lexique positif, et de l’absence de négation en sont d’éventuels indicateurs. Tout l’enjeu est alors de parvenir à développer des algorithmes suffisamment intelligents qui, à partir de sets de données, réussissent à forger une connaissance solide. Cette dernière leur permettra de déduire qu’un enchaînement de termes établis indique une certaine émotion.
En revanche certains verbatims sont parfois plus complexes. En effet, même pour un humain des énoncés peuvent être ambigus et particulièrement quand il s’agit d’ironie. Qui ne s’est jamais retrouvé perplexe devant une phrase qu’il ne savait comment interpréter ? Prenons une phrase simple et fictive :
« Un grand merci à la fuite d’eau qui vient de magnifier mon parquet. »
Pour un être humain, sa compréhension est aisée mais pour un algorithme ceci s’avère être une tâche ardue. Elle combine deux éléments très positifs qui pourraient porter à confusion quant au sens de l’énoncé. Le mot “fuite” n’est pas nécessairement négatif, notamment entouré d’autant d’éléments “positifs”. Il s’agit donc bien évidemment d’un sujet d’étude qui suscite l’intérêt de chercheurs. Si vous souhaitez approfondir ce sujet nous vous invitons à lire cette thèse très enrichissante sur le sujet.
L’analyse : principes fondamentaux
Le principe : se baser sur les traitements réalisés par les algorithmes afin d’abstraire la donnée puis en tirer des conclusions.
En termes plus concrets, l’analyse s’appuie sur des éléments statistiques usuels, des représentations graphiques des expressions les plus employées et des calculs de fréquences. C’est ici que le travail d’un analyste est capital. Son rôle est alors de repérer des thématiques dans les syntagmes employés par les internautes; une longue phase d’exploration. Un temps pendant lequel il est possible de détecter des expressions propres à une marque ou des individus utiles dans une stratégie digitale. Au travers des champs sémantiques identifiés il est possible de faire ressortir des personae en fonction de leurs éléments de langages. Ceci permet par la suite d’en déduire leurs attentes et habitudes afin d’adapter un discours de marque.

Un exemple concret
Prenons un exemple fictif d’une marque qui, pour un produit de consommation courante, aurait un discours basé sur l’aspect novateur et révolutionnaire de son produit. Une écoute des conversations sur différents canaux montrerait que lorsque les consommateurs abordent ce produit, ce qui compte pour eux ce sont avant tout l’aspect nutritif et la relation de confiance qu’ils peuvent avoir vis-à-vis de ses composants. Un outil performant permettra même à l’analyste de détecter qu’un sous-groupe (ou cluster) existe. Une composition à base d’ingrédients d’origine naturelle certifiée est importante pour ces derniers. En effet, ils sont x% à aborder le sujet et emploient des expressions très liées aux affects. Nous venons de révéler une nouvelle cible potentielle. La marque peut alors adapter sa stratégie en fonction : communiquer de façon différente sur ce produit ou développer un nouveau produit répondant aux attentes de ces consommateurs, par exemple.
Cette analyse apporte des éléments nouveaux pour les entreprises puisque les discussions écoutées proviennent d’espaces spontanés. Les internautes y abordent ces sujets sans être influencés par la structure et le contexte d’une enquête de satisfaction. De plus, la liberté octroyée par ces espaces de discussions conduit à une sincérité exacerbée. Ainsi un certain nombre de biais d’analyse sont évités et cela permet relever de nouveaux insights. Les entreprises peuvent donc se servir de ces outils dans diverses circonstances : analyse des besoins de consommateurs, avis sur leurs produits, e-réputation, discours de marques etc…
Des limites et un avenir prometteur
Dans un monde de plus en plus customer centric, où la satisfaction et la compréhension client sont au cœur des préoccupations des directions marketing ainsi que des agences, l’analyse de données sémantiques semble se présenter comme une solution idéale. Basée sur des algorithmes, elles permettent de comprendre le langage de clients et de marques et d’adapter sa stratégie en fonction.
Il convient en revanche de rester prudent sur les insights apportés par les réseaux sociaux. L’inquiétude grandissante des internautes et des gouvernements tend à réduire l’accessibilité aux données (Règlement Général sur la Protection des Données et récents scandales). En outre, les réseaux sociaux sont encore majoritairement les lieux d’expression de publics relativement jeunes. De ce fait, les données peuvent souffrir d’un biais de représentativité. De plus, trop souvent l’importance des forums est sous-estimée. Par expérience, c’est sur ces derniers que les argumentaires sont les plus étayés et qu’il est plus probable de détecter des signaux intéressants et utiles. Le choix des sources est donc capital lors d’une étude.
Si les attentes vis-à-vis de l’analyse sémantique sont élevées, c’est que cette dernière se révèle particulièrement riche d’informations. Attention cependant à ne pas déifier ces technologies. Les algorithmes ne remplacent pas l’Homme, ils viennent comme support et accompagnent les métiers d’études dans leurs réflexions. Ils restent néanmoins un formidable outil lorsqu’il s’agit d’analyser la voix des internautes.



{kind=link}